正则表达式基础知识
发布时间:2018-12-13 17:28:51编辑:丝画阁阅读(1519)
ECMAScript 3 开始支持正则表达式,其语法和 Perl 语法很类似,一个完整的正则表达式结构如下:
var expression = / pattern / flags ;
其中,模式(pattern)部分可以是任何简单或复杂的正则表达式,可以包含字符类、限定符、分组、向前查找以及反向引用。
每个正则表达式都可带有一或多个标志(flags),用以标明正则表达式的行为,正则表达式支持下列 3 个标志:
g: 表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止; i : 表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写; m:表示多行(multiline)模式,即在到达一行文本末尾时还会继续查找下一行中是否存在与模式匹配的项。
如果多个标志同时使用时,则写成:gmi 。
正则表达式的创建有两种方式: new RegExp(expression) 和 直接字面量。

exp1 和 exp2 是两个完全等价的正则表达式,
需要注意的是,传递给 RegExp 构造函数的两个参数都是字符串,不能把正则表达式字面量传递给 RegExp 构造函数。
与其他语言中的正则表达式类似,模式中使用的所有元字符都必须转义。
正则表达式中的元字符包括:
( [ { ^ $ | ) ? * + .] }
这些元字符在正则表达式中都有一或多种特殊用途,因此如果想要匹配字符串中包含的这些字符,就必须对它们进行转义。

由于 RegExp 构造函数的模式参数是字符串,所以在某些情况下要对字符进行双重转义。
所有元字符都必须双重转义,那些已经转义过的字符也是如此。

() [] {} 的区别
【1】() 的作用是提取匹配的字符串。
表达式中有几个()就会得到几个相应的匹配字符串。
比如 (s+) 表示连续空格的字符串。
【2】[] 是定义匹配的字符范围。
比如 [a-zA-Z0-9] 表示字符文本要匹配英文字符和数字。
【3】{} 一般用来表示匹配的长度。
d{3} 表示匹配三个数字。
d{1,3} 表示匹配1~3个数字。
d{3,} 表示匹配3个以上数字。
^ 与 $
【1】^ 匹配一个字符串的开头,比如 (^a) 就是匹配以字母a开头的字符串
【2】$ 匹配一个字符串的结尾,比如 (b$) 就是匹配以字母b结尾的字符串
【3】^ 还有另个一个作用就是取反,比如[^xyz] 表示匹配的字符串不包含xyz
注意问题:
如果 ^ 出现在[ ] 中一般表示取反,而出现在其他地方则是匹配字符串的开头。
^ 和 $ 配合可以有效匹配完整字符串:

d s w .
【1】d 匹配一个非负整数, 等价于 [0-9]
【2】s 匹配一个空白字符
【3】w 匹配一个英文字母或数字,等价于[0-9a-zA-Z]
【4】. 匹配除换行符以外的任意字符,等价于[^ ]
* + ?
【1】* 表示匹配前面元素0次或多次,比如 (s*) 就是匹配0个或多个空格
【2】+ 表示匹配前面元素1次或多次,比如 (d+) 就是匹配由至少1个整数组成的字符串
【3】? 表示匹配前面元素0次或1次,相当于{0,1} ,比如(w?) 就是匹配最多由1个字母或数字组成的字符串
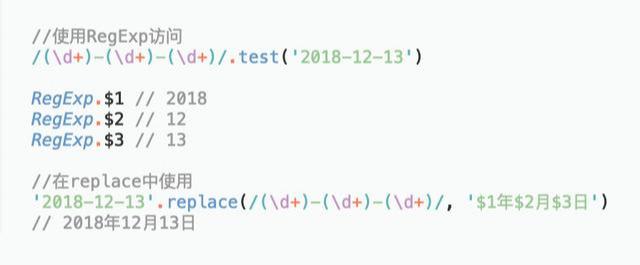
$1 与
$1-$9 存放着正则表达式中最近的9个正则表达式的提取的结果,
这些结果按照子匹配的出现顺序依次排列。
基本语法是:RegExp.$n ,这些属性是静态的,除了replace中的第二个参数可以省略 RegExp 之外,其他地方使用都要加上 RegExp
关键字:
上一篇:nginx的n种用法,你都会吗?
下一篇:PHP思维导图