内存溢出,死锁怎么办?教你如何排查
发布时间:2018-12-13 17:53:12编辑:丝画阁阅读(1508)
在Linux上编写运行C语言程序,经常会遇到程序崩溃、卡死等异常的情况。程序崩溃时最常见的就是程序运行终止,报告Segmentation fault (core dumped)错误。而程序卡死一般来源于代码逻辑的缺陷,导致了死循环、死锁等问题。总的来看,常见的程序异常问题一般可以分为非法内存访问和资源访问冲突两大类。
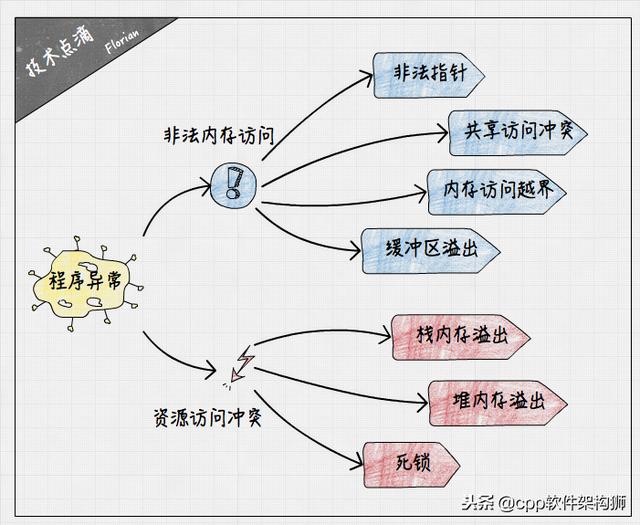
- 非法内存访问(读/写):非法指针、多线程共享数据访问冲突、内存访问越界、缓冲区溢出等。
- 资源访问冲突:栈内存溢出、堆内存溢出、死锁等。
一、非法内存访问
非法内存访问是最常见的程序异样原因,可能开发者看的“表象”不尽相同,但是很多情况下都是由于非法内存访问引起的。
1. 非法指针
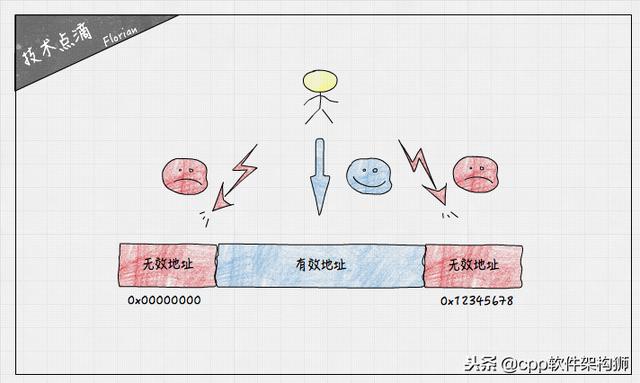
非法指针是最典型的非法内存访问案例,空指针、指向非法地址的指针是代码中最常出现的错误。
示例代码如下:
long *ptr; *ptr = 0; // 空指针 ptr = (long *)0x12345678; *ptr = 100; // 非法地址访问
无论是访问地址为0的空指针,还是用户态无效的地址,都会导致非法指针访问错误。实际编程过程中,强制类型转换一不小心就会产生非法指针,因此做强制类型转换时要格外注意,最好事先做好类型检查,以避免该问题。
2. 多线程共享数据访问冲突
在多线程程序中,非法指针的产生可能就没那么容易发现了。一般情况下,多个线程对共享的数据同时写,或者一写多读时,如果不加锁保证共享数据的同步访问,则会很容易导致数据访问冲突,继而引发非法指针、产生错误数据,甚至影响执行逻辑。
示例代码如下:
// 全局变量
long *ptr = (long *)malloc(sizeof(long));
// 线程1
if (ptr) {
*ptr = 100; // 潜在的非法地址访问
}
// 线程2
free(ptr);
ptr = NULL;
上述代码中,全局初始化了指针ptr,线程1会判断该指针不为NULL时进行写100操作,而线程2会释放ptr指向的内存,并将ptr置为NULL。虽然线程1做了判断处理,但是多线程环境下,则会出现线程2刚调用完free操作,还未来得及将ptr设为NULL
时,发生线程上下文切换,转而执行线程1的写100操作,从而引发非法地址访问。
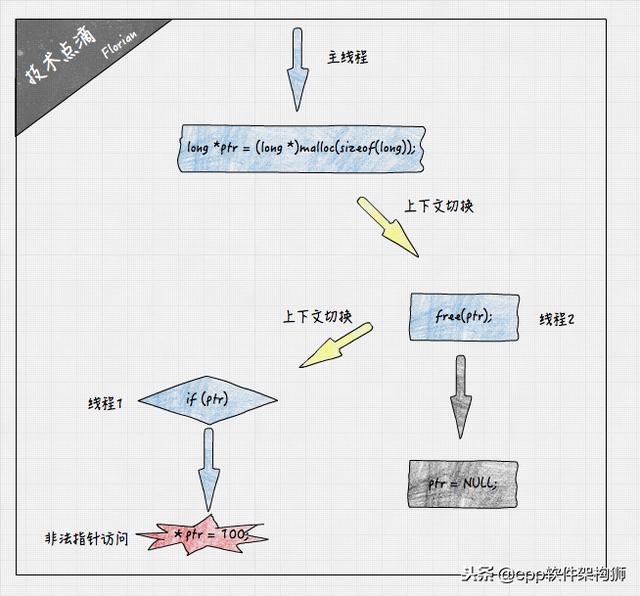
解决并发数据访问冲突的方案是使用锁同步线程。针对图中的线程同步问题,只需要在线程1和线程2的处理逻辑前,使用读写锁同步即可。操作系统或者gcc的库函数内也存在很多线程不安全的API,在使用这些API时,一定要仔细阅读相关的API文档,使用线程锁进行同步访问。
3. 内存访问越界
内存访问越界经常出现在对数组处理的过程中。本身C语言并未有对数组边界的检查机制,因此在越界访问数组内存时并不一定会产生运行时错误,但是因为越界访问继而引发的连锁反应就无法避免了。
示例代码如下:
void out_of_bound() {
long *ptr;
long buffer[] = {0};
ptr = buffer;
buffer[1] = 0; // 越界访问导致ptr被覆盖
ptr[0]++;
}
示例代码在函数out_of_bound内定义了两个变量:指针ptr和数组buffer。指针ptr指向buffer其实地址,正常情况下使用ptr[0]可以访问访问到buffer的第一个元素。然而对buffer[1]的越界写操作会直接覆盖ptr的值为0,从而导致ptr为空指针。
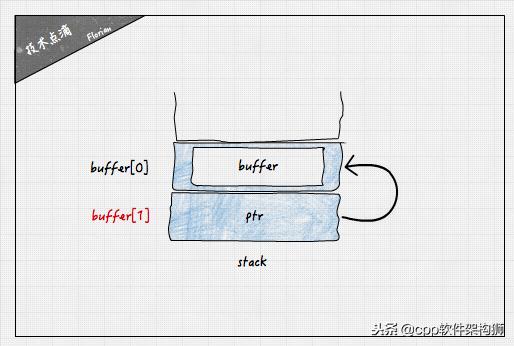
了解该问题的原因需要清楚局部变量在栈内的存储机制。在函数调用时,会将调用信息、局部变量等保存在进程的栈内。栈是从高地址到低地址增长的,因此先定义的局部变量的地址一般大于后定义的局部变量地址。上述代码中,buffer和ptr的大小都是8Byte,因此buffer[1]实际就是ptr所在的内存。这样对buffer[1]的写操作会覆盖ptr的值就不足为怪了。总之,对数组访问的时候,做好边界检查是重中之重。类似的问题也出现在对字符串的操作中,包括gcc提供的字符串库函数也存在该问题,使用时需要尤其注意。
说到边界检查,这里引申出一个话题。在对数组处理时,经常会遇到逆序遍历数组后n-1个元素的情况,有些时候一不小心就会这样实现代码:
void backScanArray(long buffer[]) {
for(unsigned int index = sizeof(buffer) / sizeof(long) - 1;
index > 0; index--) {
printf("%ld
", buffer[index]);
}
}
乍一看,代码逻辑几乎没什么问题,可是一旦buffer长度为0时,就会触发死循环了。举出这个极端的例子主要是为了说明数组边界检查时要格外小心。
4. 缓冲区溢出
缓冲区溢出攻击是系统安全领域常见的话题,其本质还是数组越界访问的一个特殊例子。为了方便讨论,这里仍举缓冲区在栈内存的例子。
我们仍使用第三节的示例代码,不过修改了一个字符:
void stack_over_flow() {
long *ptr;
long buffer[] = {0};
ptr = buffer;
buffer[3] = 0; // 缓冲区溢出攻击
ptr[0]++;
}
虽然只是修改了一个字符,但是行为已经和之前的代码完全不同了。实际在函数调用时,栈内不止保存了局部变量,还包括调用参数、调用后返回地址、调用前的rbp(栈基址寄存器)的值,俗称栈帧。
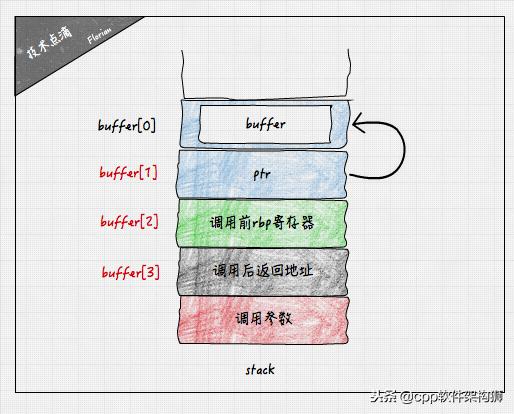
随着buffer越界的索引不断增大,可以覆盖的信息可以越来越多,甚至是上级调用的函数栈帧信息都可以被覆盖。修改buffer[3]的值意味着stack_over_flow函数调用返回后,会跳转到buffer[3]的值对应的地址上执行,而这个地址是0,程序会直接崩溃。试想如果将该值设置为一个恶意的代码入口地址,那么就意味着潜在的巨大系统安全风险。缓冲求溢出攻击的具体操作方式其实更复杂,这里只是描述了其基本思想,感兴趣的读者可以参考我之前的博文《缓冲区溢出攻击》。
二、资源访问冲突
1. 栈内存溢出
此处的栈内存溢出和前边讨论的栈内缓冲区溢出并不是同一个概念。操作系统为每个进程分配的最大的栈内存大小是有最大上限的,因此当函数的局部变量的大小超过一定大小后(考虑到进程本身使用了部分栈内存),进程的栈内存便不够使用了,于是就发生了溢出。
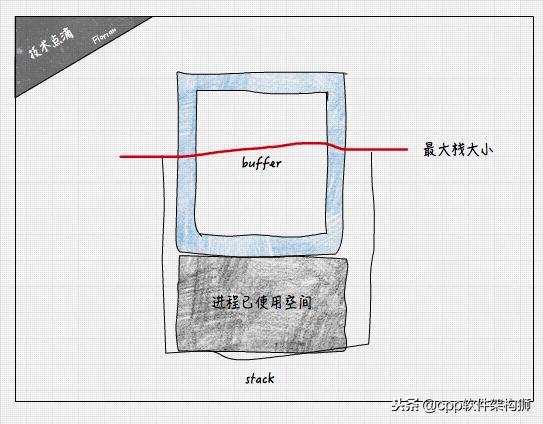
通过Linux命令可以查看当前系统设置的进程最大栈大小(单位:KB):
$ ulimit -s 8192
如果函数内申请的数组大小超过该值(实际上比该值略小),则会引发栈内存溢出异常。
另一种触发栈内存溢出的方式是左递归(无限递归):
void left_recursive() {
left_recursive();
}
由于每次函数调用都会开辟新栈帧保存函数调用信息,而左递归逻辑上是不会终止的,因此总有进程栈内存被耗尽的时候,届时便发生了栈内存溢出。
2. 堆内存溢出
堆内存溢出与栈内存溢出是同一类概念,不过进程堆空间的大小上限,因为操作系统的分页机制,理论上只受限于机器位长,即便物理内存和swap分区大小不足,也可以通过操作系统的配置进行扩展。鉴于堆内存大小的这些性质,一般的程序不太容易触发堆内存溢出异常。但是长期驻留内存的服务器进程,如果因为程序逻辑的缺陷,导致程序的部分内存一直申请,而得不到释放的话,久而久之,就会触发堆内存溢出,从而进程被操作系统强制kill掉,这就是常说的内存泄漏问题。
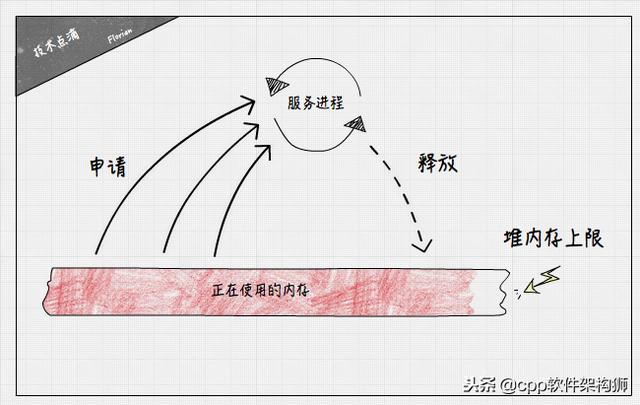
C语言使用malloc/free尽享堆内存的申请和释放,开发者编写程序时,必须小心翼翼地控制这两对函数的调用逻辑,以防申请和释放不对等诱发内存泄漏问题。而实际开发过程中,人工保证这样的准确性是十分困难的,后边我们会介绍如何使用分析工具帮我们排查程序中潜在的内存漏洞问题。
3. 死锁
前面讲到,为了解决多线程共享数据访问冲突的问题,需要使用线程锁同步线程的执行逻辑。而对锁的不正当使用,同样会产生程序异常,即死锁。死锁不会导致前边所述的直接导致程序崩溃的异常,而是会挂起进程的线程,从而导致程序的部分任务卡死,不能提供正常的服务。
最典型的死锁产生方式,就是熟知的ABBA锁。
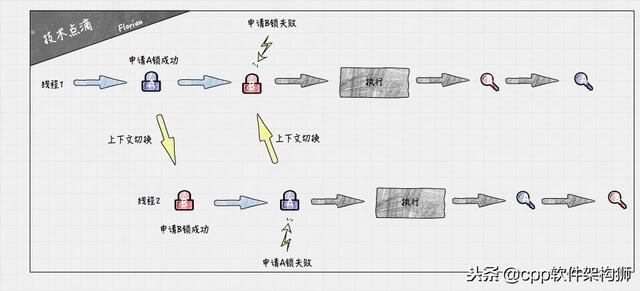
图中仍使用两个线程作为示例,假设线程1在申请完A锁后,发生了上下文切换执行线程2,线程2申请B锁成功后,再去申请A锁就会失败,从而导致线程2挂起。此时,上下文即便再次切换到线程1,线程1也无法成功申请到B锁,从而线程1也会挂起。这样,线程1和2都无法成功申请到自己想要的锁,也无法释放自己已经申请到的锁给其他其他线程使用,从而导致死锁。
解决此类死锁的办法就是让每个线程申请锁时是批量申请,要么一次性全部申请成功,要么一次性都不申请。还有一种办法就是提前预知该情况的发生,不使用两个锁同步线程,这就需要人工费力地排查潜在的死锁可能,当然,也有分析工具帮助开发者完成此类工作,稍后会作介绍。
三、程序异常解决方法
前面提到的程序异常类型,除了死循环和死锁导致进程卡死之外,其他的异常都会导致进程崩溃,触发Segmentation fault (core dumped)错误。Linux操作系统提供了允许程序core dumped时生成core dumped文件纪录程序崩溃时的“进程快照”,以供开发者分析程序的出错行为和原因,使用gdb就可以调试分析core dumped文件。而对于内存泄漏和死锁,开源工具Valgrind提供了相关的分析功能(Valgrind也提供了大量的内存监测工具,可以和core dumped文件分析互补使用)。至于死循环可以通过gdb直接调试跟踪解决,这里不再赘述。
1. CoreDumped异常分析
step 1:
让程序运行崩溃时生成core dumped文件,需要对操作系统进行简单的配置。
$ sudo ulimit -c unlimited $ sudo echo core > /proc/sys/kernel/core_pattern
第一条命令是打开系统core dumped文件生成开关,第二条命令是将进程崩溃时生成的core dumped文件放在程序执行目录下,并以core作为文件名前缀。
step 2:
接下来,以内存访问越界的例子作为示例,完整代码如下,源文件名为main.c。
void out_of_bound() {
long *ptr;
long buffer[] = {0};
ptr = buffer;
buffer[1] = 0; // 越界访问导致ptr被覆盖
ptr[0]++;
}
void main() {
out_of_bound();
}
step 3:
编译运行main.c,编译时使用需要使用-g选项,保留可执行文件调试信息,方便后续分析。
$ gcc main.c -o main -g $ ./main Segmentation fault (core dumped) $ ls core.* core.9251
我们看到程序崩溃后,生成了core dumped文件core.9251,其中9251为程序运行时进程的pid。
step 4:
调试core dumped文件。
$ gdb main core.9251 ./x: line 4: 9251 Segmentation fault (core dumped) ./main Reading symbols from demo...done. [New LWP 9251] [Thread debugging using libthread_db enabled] Using host libthread_db library "/usr/lib/libthread_db.so.1". Core was generated by `./main'. Program terminated with signal SIGSEGV, Segmentation fault. #0 0x00000000004004d6 in out_of_bound () at main.c:6 6 ptr[0]++; (gdb) backtrace #0 0x00000000004004d6 in out_of_bound () at main.c:6 #1 0x00000000004004f5 in main () at main.c:10 (gdb) print ptr $1 = (long *) 0x0 (gdb)
gdb输出了程序崩溃时代码的执行位置,main.c文件的第6行。使用backtrace命令可以打印当时的函数调用栈信息,以方便定位出错的上层调用逻辑。使用print命令打印ptr指针的值,确实为0,与我们之前的讨论一致。上面分析仅仅是一个非常简单的示例,实际开发过程中遇到的出错位置可能更隐蔽,甚至是库函数的二进制代码,届时需要根据个人经验来具体问题具体分析了。
2. 使用Valgrind进行内存泄漏和死锁检测
Valgrind是非常强大的内存调试、内存泄漏检测以及性能分析工具,它可以模拟执行用户二进制程序,帮助用户分析潜在的内存泄漏和死锁的可能逻辑。
step 1:
开源工具Valgrind提供了源码tar包,需要下载、编译、安装使用(最新版本Valgrind如果编译报错,请将gcc更新到最新版本)。
$ wget http://valgrind.org/downloads/valgrind-3.12.0.tar.bz2 $ tar xf valgrind-3.12.0.tar.bz2 $ cd valgrind-3.12.0 $ ./configure --prefix=/usr/local/ $ make && sudo make install $ valgrind --version valgrind-3.12.0
step 2:
准备内存泄漏示例代码。
#includevoid main() { malloc(4); }
step 3:
使用Valgrind进行内存检测。
$ valgrind --tool=memcheck --leak-check=full ./main ==24470== Memcheck, a memory error detector ==24470== Copyright (C) 2002-2015, and GNU GPL'd, by Julian Seward et al. ==24470== Using Valgrind-3.12.0 and LibVEX; rerun with -h for copyright info ==24470== Command: ./main ==24470== ==24470== ==24470== HEAP SUMMARY: ==24470== in use at exit: 4 bytes in 1 blocks ==24470== total heap usage: 1 allocs, 0 frees, 4 bytes allocated ==24470== ==24470== LEAK SUMMARY: ==24470== definitely lost: 0 bytes in 0 blocks ==24470== indirectly lost: 0 bytes in 0 blocks ==24470== possibly lost: 0 bytes in 0 blocks ==24470== still reachable: 4 bytes in 1 blocks ==24470== suppressed: 0 bytes in 0 blocks ==24470== Reachable blocks (those to which a pointer was found) are not shown. ==24470== To see them, rerun with: --leak-check=full --show-leak-kinds=all ==24470== ==24470== For counts of detected and suppressed errors, rerun with: -v ==24470== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
我们看到LEAK SUMMARY节内容中显示程序退出时,仍有4B的内存可以访问,也就是产生了内存泄漏。
step 4:
准备死锁示例代码,我们实现了前面讨论的ABBA锁的代码。
#include#include #include pthread_mutex_t lock_A = PTHREAD_MUTEX_INITIALIZER; pthread_mutex_t lock_B = PTHREAD_MUTEX_INITIALIZER; void *run1(void *args) { pthread_mutex_lock(&lock_A); sleep(1); pthread_mutex_lock(&lock_B); pthread_mutex_unlock(&lock_B); pthread_mutex_unlock(&lock_A); } void *run2(void *args) { pthread_mutex_lock(&lock_B); sleep(1); pthread_mutex_lock(&lock_A); pthread_mutex_unlock(&lock_A); pthread_mutex_unlock(&lock_B); } void main() { pthread_t tid[2]; if (pthread_create(&tid[0], NULL, &run1, NULL) != 0) { exit(1); } if (pthread_create(&tid[1], NULL, &run2, NULL) != 0) { exit(1); } pthread_join(tid[0], NULL); pthread_join(tid[1], NULL); pthread_mutex_destroy(&lock_A); pthread_mutex_destroy(&lock_B); }
step 5:
编译(需要链接pthread库),并使用Valgrind进行死锁检测。
$ gcc main.c -o main -g -lpthread $ valgrind --tool=helgrind ./main ==24652== Helgrind, a thread error detector ==24652== Copyright (C) 2007-2015, and GNU GPL'd, by OpenWorks LLP et al. ==24652== Using Valgrind-3.12.0 and LibVEX; rerun with -h for copyright info ==24652== Command: ./main ==24652== Ctrl + C ==24652== ==24652== Process terminating with default action of signal 2 (SIGINT) ==24652== at 0x4E4568D: pthread_join (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4C2EAA7: pthread_join_WRK (hg_intercepts.c:553) ==24652== by 0x4C32908: pthread_join (hg_intercepts.c:572) ==24652== by 0x400806: main (main.c:39) ==24652== ---Thread-Announcement------------------------------------------ ==24652== ==24652== Thread #2 was created ==24652== at 0x51427AE: clone (in /usr/lib/libc-2.24.so) ==24652== by 0x4E431A9: create_thread (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4E44C12: pthread_create@@GLIBC_2.2.5 (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4C31810: pthread_create_WRK (hg_intercepts.c:427) ==24652== by 0x4C328FD: pthread_create@* (hg_intercepts.c:460) ==24652== by 0x4007BA: main (main.c:30) ==24652== ==24652== ---------------------------------------------------------------- ==24652== ==24652== Thread #2: Exiting thread still holds 1 lock ==24652== at 0x4E4CF1C: __lll_lock_wait (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4E46B44: pthread_mutex_lock (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4C2EE18: mutex_lock_WRK (hg_intercepts.c:894) ==24652== by 0x4C32CE1: pthread_mutex_lock (hg_intercepts.c:917) ==24652== by 0x40073F: run1 (main.c:12) ==24652== by 0x4C31A04: mythread_wrapper (hg_intercepts.c:389) ==24652== by 0x4E44453: start_thread (in /usr/lib/libpthread-2.24.so) ==24652== ==24652== ---Thread-Announcement------------------------------------------ ==24652== ==24652== Thread #3 was created ==24652== at 0x51427AE: clone (in /usr/lib/libc-2.24.so) ==24652== by 0x4E431A9: create_thread (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4E44C12: pthread_create@@GLIBC_2.2.5 (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4C31810: pthread_create_WRK (hg_intercepts.c:427) ==24652== by 0x4C328FD: pthread_create@* (hg_intercepts.c:460) ==24652== by 0x4007E7: main (main.c:34) ==24652== ==24652== ---------------------------------------------------------------- ==24652== ==24652== Thread #3: Exiting thread still holds 1 lock ==24652== at 0x4E4CF1C: __lll_lock_wait (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4E46B44: pthread_mutex_lock (in /usr/lib/libpthread-2.24.so) ==24652== by 0x4C2EE18: mutex_lock_WRK (hg_intercepts.c:894) ==24652== by 0x4C32CE1: pthread_mutex_lock (hg_intercepts.c:917) ==24652== by 0x400780: run2 (main.c:21) ==24652== by 0x4C31A04: mythread_wrapper (hg_intercepts.c:389) ==24652== by 0x4E44453: start_thread (in /usr/lib/libpthread-2.24.so) ==24652== ==24652== ==24652== For counts of detected and suppressed errors, rerun with: -v ==24652== Use --history-level=approx or =none to gain increased speed, at ==24652== the cost of reduced accuracy of conflicting-access information ==24652== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 1 from 1)
第8行日志,程序因为死锁卡死,使用Ctrl+C强制退出。第27和48显示:线程2和3(主线程编号为1)在退出时仍然格持有1个锁,很明显,这两个线程相互死锁了,与之前的讨论一致。
总结
本文从Linux上C语言编程中遇到的异常开始讨论,将异常大致分为非法内存访问和资源访问冲突两大类,并对每类典型的案例做了解释和说明,最后通过core dumped文件分析和Valgrind工具的测试,给读者提供了遇到程序运行时异常时的解决方案。希望看到此文的读者,在以后遇到程序异常时都能泰然自若,冷静分析,顺利地找到问题的根源,便不枉费笔者撰写此文之心血。
参考资料
- coredump简介与coredump原因总结: http://blog.csdn.net/newnewman80/article/details/8173770
- C语言申请内存时堆栈大小限制: http://blog.csdn.net/xxxxxx91116/article/details/10068555
- Linux malloc大内存的方法: http://www.cfanz.cn/index.php?c=article&a=read&id=103888
- valgrind 的使用简介: http://blog.csdn.net/sduliulun/article/details/7732906
- 一个 Linux 上分析死锁的简单方法: http://www.ibm.com/developerworks/cn/linux/l-cn-deadlock/
关键字:
上一篇:MySQL批量SQL插入性能优化
下一篇:统计一下你写过多少代码